近年、デジタル的あるいは情報学的手法を取り入れた「デジタル人文学(Digital Humanities)」研究が生み出されつつありますが、そのような研究の共通基盤は未だ作られておらず、研究手法や課題の共有が行われにくい状況にあります。
文学研究科の人文知連携拠点では、「文学研究科の諸専修が蓄積してきた研究成果を横断的に連携させることを通じて、新しい学知の創造を目指す」というミッションのもと、人文社会に関わる研究手法や成果の普及を目指しています。
今回、新たな試みとして、デジタル的手法を取り入れた優れた研究を行う研究者へのインタビューを通じて、研究手法の導入や創意工夫、成果や研究の課題について語りあう「デジタル人文学Round Table@京大ぶんこも」が立ち上げられました。
2025年11月27日(木)に開催された記念すべき第1回のダイアログパートナーは、文学研究科・英米文学専修の南谷奉良さん。
南谷さんが編者・著者を務めた『生成AI×ロボティクス』(春風社)より、カズオ・イシグロの『Klara and the Sun』を題材としたデジタル人文学研究の試みについてお聞きしました。
1. 南谷さんの研究
天野恭子(ファシリテーター):記念すべき第1回のダイアログパートナーは南谷奉良先生です。『生成AI×ロボティクス』の編者でもありますし、その中の一章の論考も書いておられます。今日はその論考について詳しくお話伺えたらと思っています。
南谷奉良(ダイアログパートナー):私の専門はアイルランドの作家のJames Joyce(1882–1941)の研究です。これまではジョイスの作品の中に登場する動物の表象に関心をもっていて、19世紀から20世紀初頭にかけての文学作品で動物、犬、猫、馬、牛、象、絶滅した古生物や恐竜といった存在がどのように描かれていたのかを研究してきました。例えば、猫はとても愛らしい、アイコニックな存在になっていますけれども、19世紀だとその性欲の強さから忌まわしい生き物というステータスがまだ残っていました。犬も同様で、まだ狂犬病が根絶していなかったために非常に恐れられていた動物でした。つまり今の私たちの認識とは異なっている、当時の動物の表象を研究していたわけです。そういう研究をやっていると、当然のことながら動物の痛みに触れることになりますが、その動物の痛みを研究していた先に、ロボットが出てきました。それがまずひとつ、今回の論文で、カズオイシグロの『Klara and the Sun(2021)(邦題:クララとお日さま)』を扱うことになった経緯だと言えます。また、ロボットに関心を抱いたタイミングや、生成AIが登場したときにちょうど重なったのが、名古屋大学と京都大学で行っている「先導的人文学・社会科学研究推進事業」でした。私はこのプロジェクトの第3班「言語獲得と主体化プロセス」の中で、テキストマイニング・生成AIを研究しており、同プロジェクトの叢書第2巻として『生成AI×ロボティクス』の出版に至った次第です。
先導的人文学・社会科学研究推進事業「人間・社会・自然の来歴と未来―「人新世」における人間性の根本を問う」(Anthropocenic Actors and Agency in Humanity, Society, and Nature, 略称AAA;研究代表者:中村靖子)私は人文学における手法のシェアということに関して非常に強い問題意識を持っています。専門知を公開することを目指した活動をこれまでずっと行ってきていて、今現在行っているものの一つが、「終わらない読書会―22世紀の人文学に向けて」です。若手講師の方にご登壇いただいて、ヒト・動物・モノ・機械・自然を主題とした文学作品などを扱い、専門的な知見をアカデミア以外の一般の参加者の方たちにシェアする読書会です。最近では「文系のための生成AI研究会」という企画も始めました。最初は50名くらいでと思っていたのですが、現時点で440名が集まっていて、生成AIに対する関心の高さがうかがえるところです。参加者には先生方や学生の方、また一般の方も含まれています。多くの方がAIの使い方に迷っておられると思うので、その活用法をシェアすることを目的にしています。


・教育用匿名チャットアプリOutisと生成AI機能を加えたAivis
天野:南谷さんが取り組まれているアプリ開発についてもお聞きしていいですか。
南谷:これは私が前任校にいた時、システムエンジニアと開発したアプリです。2016、2017年ぐらいにスマートフォンが普及してくるなかで、教室のなかで明確に変化がありました。学生たちが一斉に机の下を見始めたんですよね。教壇の方を見てくれなくなった。これはちょっと困ったなと思って。それでどうしたら授業を聞いてもらえるのかなっていうのを考えた時に、スマホを使う何かを作ろうと考えました。それからきっかけとしてはもう一つあって、当時はアクティブラーニング教育を推進する方策がとられはじめたときなのですが、そういう授業を行うときに、教室の中には発言することや誰かと話すことそのものを強く忌避する学生がいることに気づきました。ある授業回で、ペアになって英語で道案内をしてみましょうというワークをやったら、いつもその授業で一人でいた学生が、私がその課題を言った瞬間にすごく嫌そうな顔をしたんですね。その顔がちょっと忘れられなくて。発言が苦手な学生の意向を無視して、無理やりアクティブラーニングのタスクに参加させることの粗忽な暴力みたいなのを強く感じました。アクティブラーニングに参加するための心理的障壁を下げたいということも手伝って、スマホを使って、かつ音声で発言しなくても発言できるチャットアプリを作れないかということで、システムエンジニアの友人と協力しこの匿名チャットアプリをつくりました。
2023年には、生成AI機能を加えて、AIVISとして授業や読書会、研究会で使用しています。メッセージの送信だけではなく、ChatGPTの最新バージョンに基づいたテキスト生成や画像生成ができるようにしています。今個人のアカウントでそれぞれのユーザーがテキスト生成や画像生成を行っているわけですけど、それを一つのプラットフォーム内で複数のユーザーでの生成をやりたかったんです。編著書のなかでも触れましたが、「フリーミアム問題」の解決方法の一つでもあります。
『生成AI×ロボティクス』p. 192 コラム2「生成AIとフリーミアム問題 —新しいデジタルデバイド」2. 「”OK, AF. We same side” —置き換え・代替可能性からみる『クララとお日さま』の特別な言葉」
・概要
天野:今日お話を伺おうと思っていた本の中の、南谷先生自身の論考「”OK, AF. We same side” —置き換え・代替可能性からみる『クララとお日さま』の特別な言葉」についてです。南谷先生自身の言葉によると、AF (artificial friend)であるクララの一人称語りを通じて、代替可能性に直面する人間およびAIロボットの脆弱的な存在条件を描き出しているのが、このカズオイシグロの『クララとお日さま』です。この「置き換え」および「代替」の主題の分析にテキストマイニングの手法を用いられています。
南谷:テキストマイニング手法は、先ほどご紹介した先導的人文学のプロジェクトを通じて初めて学びました。最初はどういう風に使っていいか全くわからなかったんですけれども、テキストの内容、質に応じてテキストマイニング方法が決まるんじゃないかと考えました。この論文の執筆に至った経緯をお話したいと思うんですけれども、この作品では、Artificial Friend(AF)というロボットのクララが、ジョージーとそのお母さんに購入されるんですね。なぜクララが購入されたかというと、ジョージーは余命いくばくもないと考えられていた病気に罹っているために、彼女の代替物としての役割が期待されているからです。家庭のなかに入ってジョージーを観察しながら学習し、いずれ亡くなった場合に備えて、ジョージーの代わりになる存在になってもらいたいということで、クララが購入されたわけです。家庭に入ってきたクララですが、家政婦のメラニアさんからは厳しい言葉ばかり受けることになります。例えば、“Plan? Listen, AF. You make things worse, I fuck come dismantle you(計画?聞けAF。もし何かやって悪くしたらAFぶっ壊す。)”なんて言われたりします。断片的な言葉が使われていることに加えて、罵倒語やいわゆるFワードなどがクララに向けられます。
私の疑問は、なぜ家政婦(メラニア)が断片的な非標準語を話すのか?なぜメラニアのセリフには罵倒語やFワードが使われているのか?他の登場人物とどのように発話が差異化されているのか?メラニアの発話の特性を印象によらずどのように論証するのか?ということです。伝統的な文学研究の中でもメラニアの発話は特異性を論じることはできると思いますが、テキストマイニングを使えば、「客観的な」データとして提示できるのではないかと考えました。それがこの論文を書いたきっかけになります。
・データの構築
南谷:まず『クララとお日さま』の文字起こし、コーパスの作成から始めました。これは2021年に出た作品なので、当然のことながらInternet Archiveなどのウェブサイトにテキストが挙げられているわけでもなく、全部自分で文字起こしをしないといけません。RAの方を雇用して手伝ってもらって、正確な文字起こしをして論文を書くのに、だいたい2年ぐらいかかりました。
天野:今だったらOCR(Optical Character Recognition, 光学文字認識)で簡単にできますか?
南谷:OCRがやっぱりうまくいかなかったりしますね。本当に正確でないといけないので。ここ(人力での文字起こし)にすごい時間がかかってしまう。その後、クララの一人称の語りと、それとは別に登場人物ごとの直接話法を抽出するという作業があるので、それを分けて集計しました。この切り分けは人力で行いました。
天野:そういう切り分けに使えるツールみたいなのはないものですか?
南谷:誰が発話してるかを分けるツールはないので、やっぱり全部人力ですね。直接話法が並んでいる場合などは、文脈から判断しないといけません。これはメラニアで、これはクララで、といちいち全部自分でつけました。
天野:すごい大変そうですね。私の研究でもそうなんですけど、デジタル的な手法を使おうと思ってまずデータを作る時に、データを人力で作り込むという過程がありますね、やっぱり。
オーディエンス:もしかしたら、誰々のセリフっていうのは、人間が読んだら分かるのでは。読み手を変えて音声で読んで、それをディクテーションして行く方がテキスト化が速かったりしませんか。
南谷:なるほど、そういう方法があるわけですね。
オーディエンス:昔、音声認識があまりまだ良くなかった時に、音声認識ソフトを自分でトレーニングすると精度が上がるっていう時期があったんですよ。その時は、インタビューしたやつをそのまま(音声認識ソフトに)聞き取らせるのが困難だったので、自分の声だと音声認識ソフトが慣れてるから、自分で全部シャドーイングしてプレーンテキストにあげたりとかしてました。それからすると、朗読しちゃって、それを元のテキストを見ながらチェックするのが早いかもしれないと思いました。とにかくデータ整理とデータクリーニングが本当に一番大変な作業なので、著作権が切れてない新しい作品のときにそれをどうするのかというのは思っていて、手法を教えて欲しいなと思います。
天野:古典もね、結構、データ作ってタグ付けして分析するのに時間と手間がかかりますよね。手作業的な部分がどうしてもあったりします。
・『クララとお日さま』登場人物の呼び名の分析
天野:呼称およびあだ名の分析、というところの説明をお願いします。
南谷:計量分析ですが、名詞が一番やりやすいんですよね、動詞なんかに比べると変化が少なくて。名詞を抽出したあとで、各登場人物が用いるその他の人物の呼び方に着目してみると面白いと思ったんですね。というのは、実際に登場人物ごとにどういうふうに呼ばれているのかを見た時に、それぞれの特徴みたいなものが出てくるからです。例えばクララは、メラニアのことをずっとHousekeeperと呼んでいます。固有名詞では呼ばない。ジョージーはお母さんのことをアメリカ綴りのMomと呼んでいますが、友達のリックはイギリス綴りのMumを使っています。イギリス英語とアメリカ英語の使い分けがはっきりと出ている。これがデータとして出てきたのがすごく嬉しかったです。
もう一つ出てきた謎は、なぜクララがMumを使っているのか、ということです。クララは普段、ジョージーの母親に対しては、Motherという呼称を用います。そこで、なぜMumって言ってるんだろうと気づいて、わかったことがありました。先程、クララはジョージーの身代わりになるために購入されたAFだとお話しましたが、あるシーンでお母さんが、クララに対してジョージーの真似をするよう依頼するところがあります。その真似をする時に、クララが(ジョージーと同様に)アメリカ綴りのMomを使っているとことがわかりました。
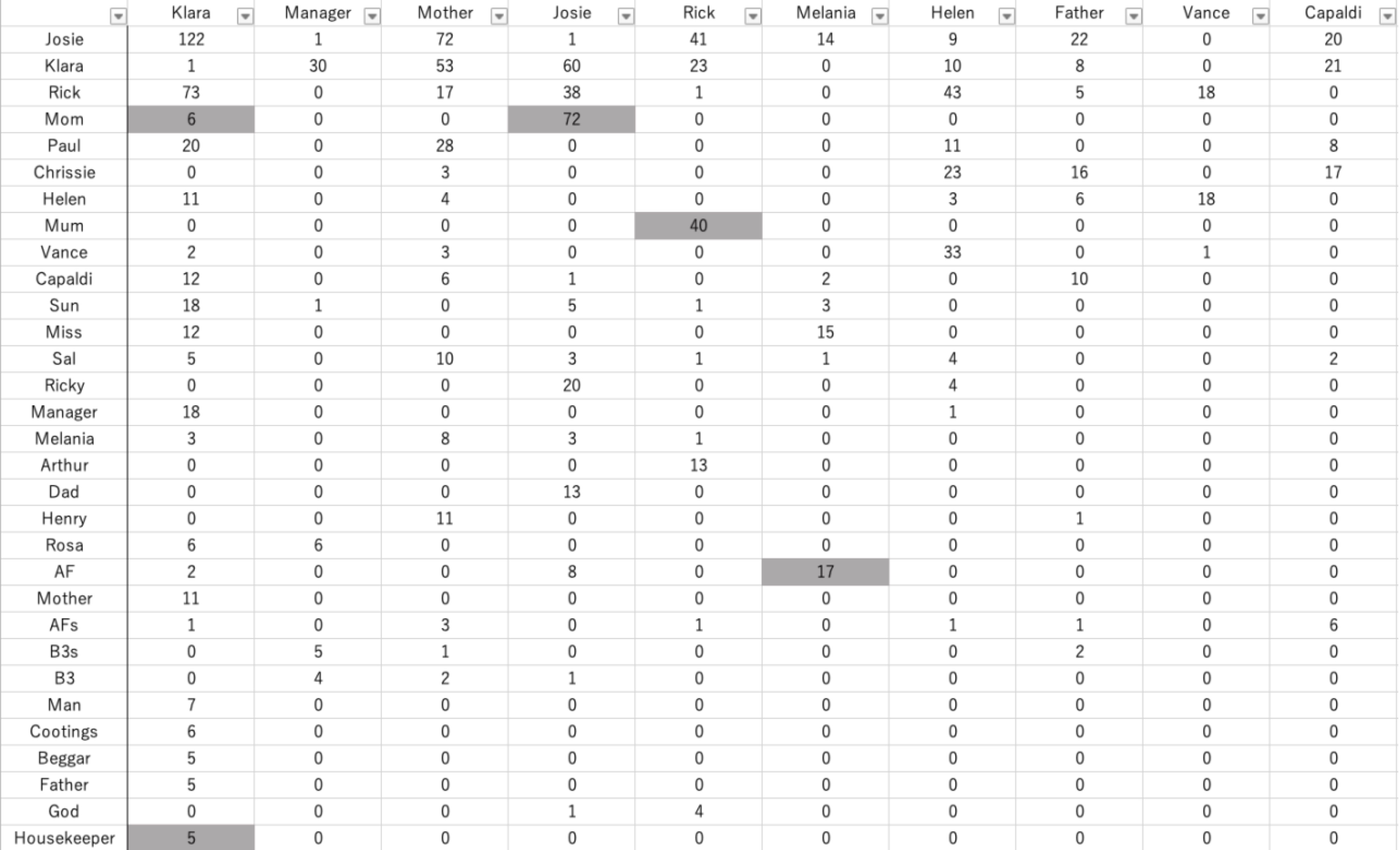
・イディオレクトの分析と精読
南谷:その場面では、お母さんはジョージーのふりをして話をしてるクララを信じきって、自分の娘として話してるんですけど、ある時にクララがこういうことを言うんですね。“There’s special help coming. Something no one’s thought of yet. Then I’ll be well again(何か特別な助けが来るから、すぐ良くなる).”と。クララがこれを言った時に、お母さんはこれをおよそジョージーらしくない言葉として認識しました。だからこそ「どういうこと?これ誰が喋ってるの?」と言うわけです。ここで鍵になるのは、“There’s special help coming”という言葉が、ジョージーの言葉ではなくて、クララの言葉になってるんじゃないかということです。Specialという形容詞は、クララに固有の用法で用いられているイディオレクトになっているのはないかと考えました。
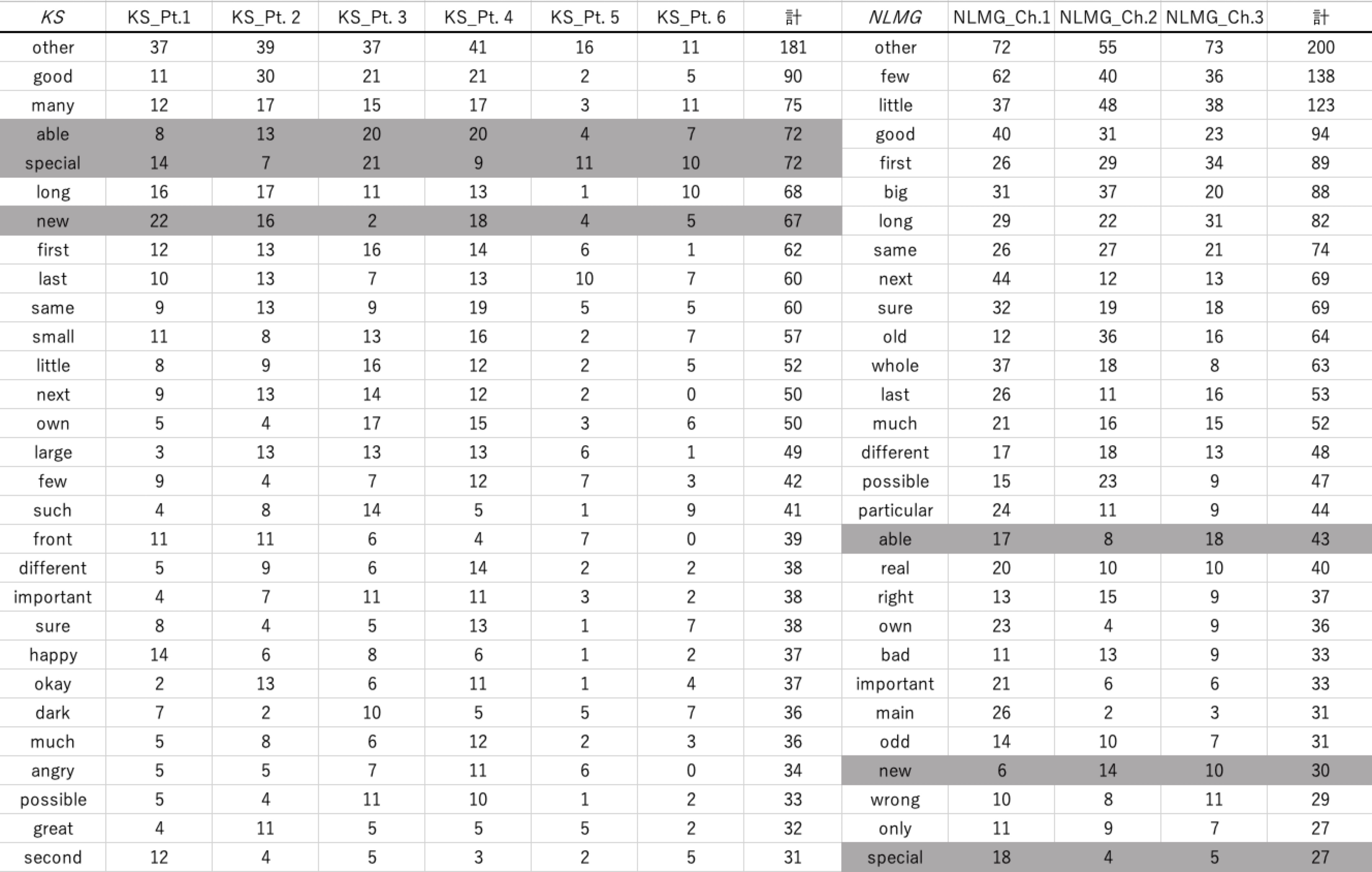
実際に形容詞の出現を調べたところ、非常に面白い結果が出てきました。図6の左が『Klara and the Sun』から上位頻度の形容詞を抽出した結果です。図6の右が『Never Let Me Go』というイシグロの別の作品の形容詞の分析です。こちらでもspecialは高い頻度で使用されているのですが、それでも圧倒的に『Klara and the Sun』での方が高い位置を占めていることがわかります。ここが「代替」というモチーフに関わるのですが、何とでも入れ替え得る、主体のアイデンティティなんか存在しないのだ、という価値観が出回っている本作品の中で、それでもspecialなものがあるのだという主題が。代替に対するアンチテーゼとしてそのspecialという言葉が浮上してきた、というのがテキストマイニングの手法によって判明したことになります。
天野:最初の、呼称を取り出して並べて、クララのMomの使い方に気づいたっていうのは、データ駆動という感じだったんですかね。データから、それまで考えていなかったことに気付いて。一方で、テキストを見ていた時に、specialっていう言葉がキーになっていると気付いて、今度はspecialを含む形容詞を調べたというのは、人間、自分の考えから分析へと駆動したっていう感じですね。その両方のやり方があると思っていて。
オーディエンス:探索するんじゃなくて、仮説検証的な使い方もあるということですね。
天野:データ駆動ばかりではなくて、自分があれ?と思ったことを分析してみる、統計を出してみる、というそういう方向の、両方あるんだなと思いました。
—『クララとお日さま』(KS) と『わたしを離さないで』(NLMG) の比較
・トピックモデリングとイディオレクト
天野:ほかのグラフのところもお伺いしていいですか?この図(p. 251, 図3)、トピックモデリングという形式ですね。どういう風に見たらいいか教えていただけますか。
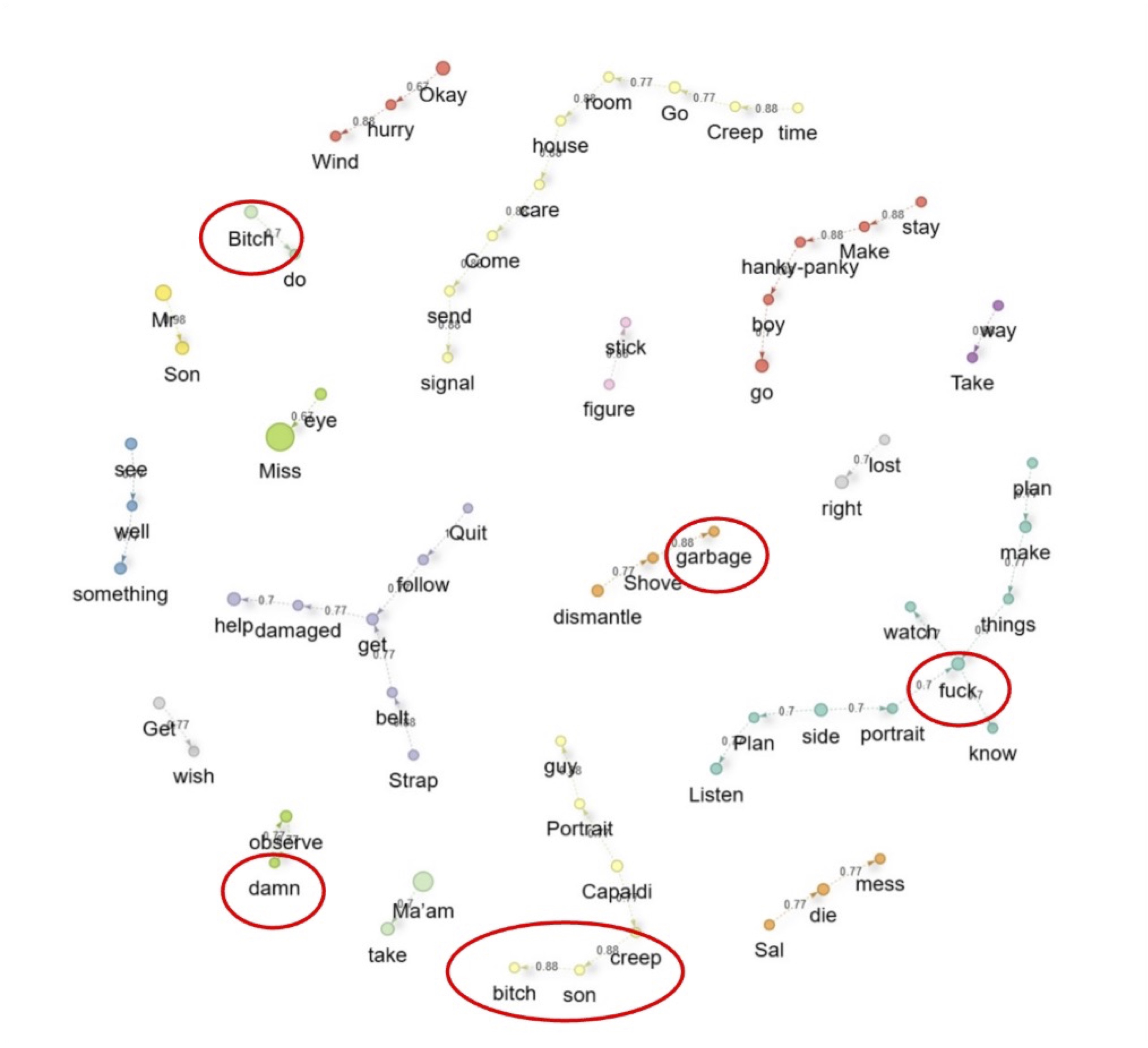
南谷:コーパス作成のなかで、家政婦のメラニアのセリフだけを集めた「メラニア・ファイル」があるわけですけれども、彼女が用いる単語が、ほかの単語とどういうふうに関連しているのか、共起しやすいのかというのを示した図です。トピックモデリングを用いたのは、彼女の発言の中で罵倒表現や品のない言葉が、どれだけ特徴的に現れているのかを示すためでした。メラニアはジョージーのお母さんに対して話す時は丁寧な言葉を使うのですが、クララと話す時、そして特に彼女が危険視している人物が関わるときに、罵り言葉が現れる傾向があります。
天野:論考の中では「罵り言葉や悪態を主成分とするトピックが優位に形成され、他の語彙クラスターから明確に分離している(p. 250)」と説明しておられます。
南谷:bitchやdamnといった語が現れる時に、それが他のクラスターから明確に分離していることを示したかったんです。罵倒語は、クララに話しているとき、また、メラニアが敵視しているカパルディ氏という人物に関わる場面で使われていますよね。罵倒語がportraitという語と共起して使われているのがわかります。このportraitというのは、カパルディ氏が制作しているジョージーの姿をした人工物のことで、クララの学習データを入れようと考えている人工的な模型のことです。他の人物の発言には罵倒語は混じらないし、あっても回数が少ない。つまり、メラニアは罵倒語を使う人物として造形されていると示すことができたわけです。
天野:個人の言葉遣いの癖が分析できるかどうかって、みんなすごい興味があると思います。文献の考察で重要なことになってくると思っていて。だから、そういう手法の一つとして、トピックモデリングなどが有効なのかどうかに関心があります。
天野:こっちの図(p. 251, 図2)の見せ方っていうのは、どういう利点がありますか?
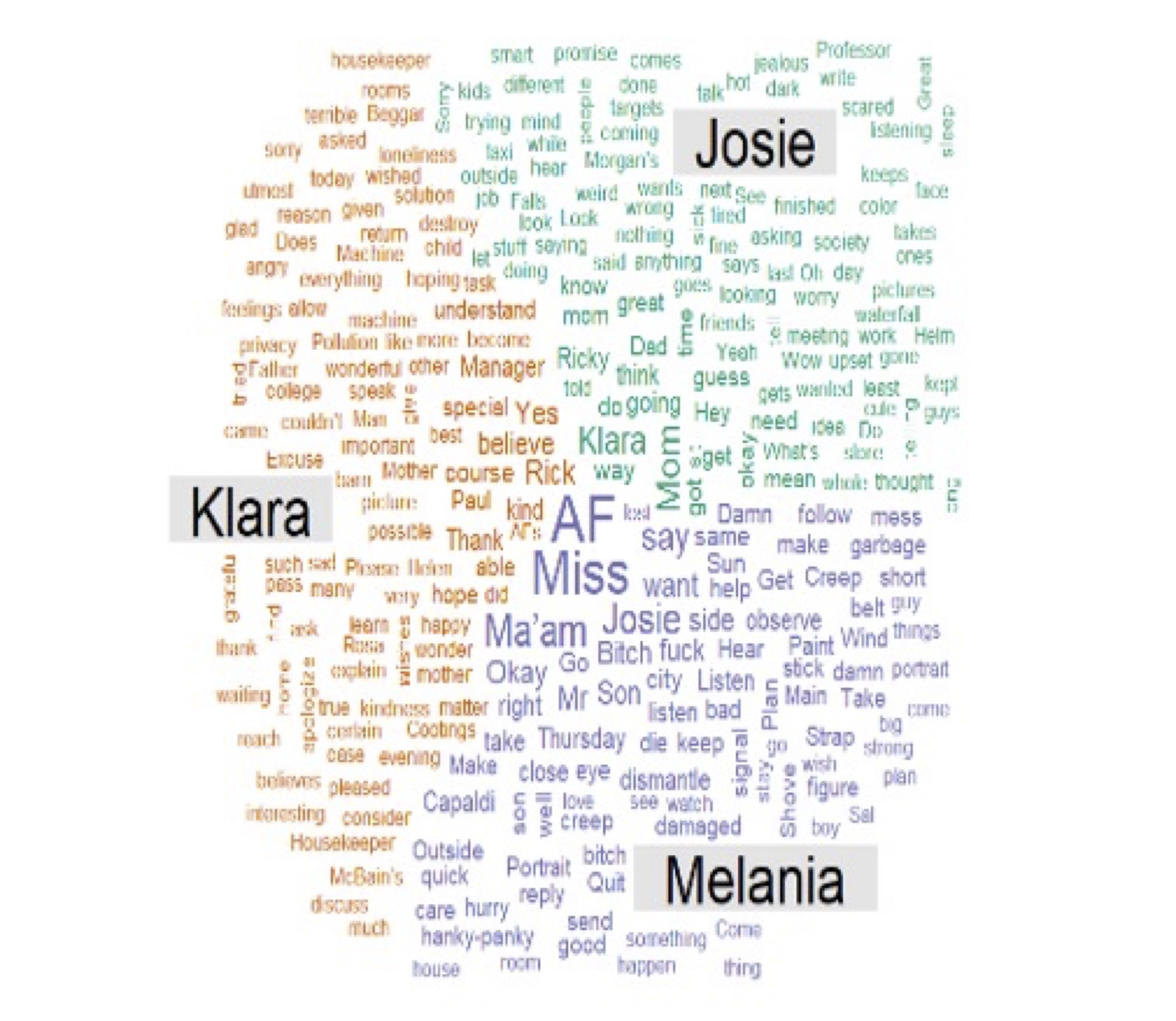
南谷:これは内容語で分析しているものです。名詞、動詞、形容詞が混じっていますが、その頻度を主要登場人物3人(クララ、ジョージー、メラニア)で比較した結果です。多く使ってる語ほど図の中心に来て、字の大きさも大きくなります。呼称が中心になるのは当然だと思うんですけど、メラニアでは中心に近いところにbitchとかfuckなどの語があります。この図を見ると、その人物は何を話題として上げやすいのか、どんな言葉をよく使うのかを見つけることができます。クララに関してはspecialが非常に中心に近く、多く使われていることが明示されています。またクララはロボットとして所有者の命令を聞く存在なので、yesという語が中心に近く、大きく表示されていることもわかります。一方で、語彙の頻度、出現数が多いからといって重要であるっていうのもちょっとまずくて。1回しか登場しないにもかかわらず、極めて重要なこともあるので、ここは精読の手法と接続して分析する必要があります。
オーディエンス:メラニアの言葉がすごい目立ってるんですけど、真ん中に大きく。これはメラニアの発言の中で頻度が高いから(文字が)大きくなる?
南谷:メラニアは元々発言が少ないので、その中でAFとかMissとか、特定の語の頻度が高くなりやすいです。メラニアの発話トークンが少ないので、例えば(メラニアの発語である)AFが5回、(クララの発語である)リックも5回だと、AFが大きくなってしまう。ワードクラウドを出す時に文字の大きさを調整することもできるので、大きさそのものはあまり重要視しなくてもいいと思います。3人の文字の大きさを同じ基準で見ることはできません。文字の大きさということだけで判断すると、ミスリーディングな図になってしまうと思います。
天野:論考の中でメラニアの言葉遣いを詳しく考察されていて、主節と従属節のある階層構造がほとんどないとか、be動詞や過去形の欠落といった言語的特徴について。あるいは、バーンスタインの社会言語学的な区分の「精密コード」と「制限コード」によると制限コードに当たるなど。こういったことはどうやって分析しますか?
南谷:文法解析自体は私が行っていますが、ChatGPTで言語的特徴を分析してみたところ、かなり正確に行うことができました。一方で生成AIは、形態素解析自体は未だ苦手なのかなという印象を持っています。こういう分析を探索的にやって、情報を使えるかどうかを選んでいくのは必要なんですが、データを恣意的に動かせるようになると、仮説検証的な観点からはまずいです。テキストマイニングの結果を出すときに、図だけを掲載すると信頼性がないなと思ったので、数値の表(図6)を載せたんですけど、結局最後は全部自分の手で数えました。こちらの認識不足とかデータミスも多分あるでしょうから。信頼性のあるデータ作りはきちんとやらなくてはいけないのですが、自分の中でまだその手法自体は手探り状態でした。今回はDHと伝統的な人文学が両立することができる、バランスのある論文を書いて、そのフォーマットを作りたいと考えました。
3. LLM、生成AIによる研究の変化はあるか
天野:私もテキストの分析をやってきたのですが、タグ付けとかでデータを作りこんで、それを使って解析しようと思って進めてきたのが、大規模言語モデルになってから、みんなそういうの(タグ付けしたデータ)もういいやみたいに、一気に流れ変わったっていう、自分の周りの感触があるんですけど。
南谷:英文学分野ではまだ、生成AIを全面的に活用している研究者の方は、そんなに聞かないです。データを作りこんでの統計分析みたいなものが、すべてを塗り替えていくわけでもないと思いますが、現時点では、そうですね。ただ「今できないことが割とすぐできるようになる」現象をこの数年で見てきているので……。
天野:データを作りこんで改良して、やっとちょっとまともな分析結果が出たかなとなって、それをじゃあ良さそうだから今後もっと広げてやっていこうっていう時に、もう次の技術が出てきちゃってるということがあります。
・分析データの信頼性
南谷:自分がやってるのはテキストマイニングですが、自分が期待する結果が出てくれない時に、後でいじることもできて、ある単語を除外したりすることで図やグラフをきれいに出力できました。その作業自体はとてもまずいですよね。その作成したデータ自体を共有しているわけでもないですし、論者の自分だけがデータを持っていて、結果を出すときにもある程度自分で調整できてしまう。結果を見やすいように表示することは大事とは思いますが、客観的な証拠では全くなくなってしまいます。生成AIが普及してくると、自分が欲しい成果が出るようにデータを集めて出力させるというチェリーピッキングが今後多く起こりそうで、それが怖いですね。
オーディエンス:実験系の分野でも、統計分析でデータが多いといわゆる有意差が出やすいっていうのがあって、いい結果になるようにデータを工夫するp-hackingっていうのがすでにかなり問題視されていて。結果を美しく見せるためにデータを後から工夫するのはよくない研究手法だという認識があります。文献だったら、後から増やしたりできないんだと思いますけど。最近では、研究を始める前に、データをとるプロトコルとか分析方法まで全部レジスターして、パブリックに見えるようにして、その通りやって論文化するという仕組みができてきています。
オーディエンス:それが実験系の人たちは慣れてるんですよね。そういうことが簡単にできちゃうっていうのを互いに知っている、別に縛りを入れてるというか。だけど人文系は今そういう倫理がない中で、急に結構いいツールが来ちゃったんで、その手のことをしちゃいけないこと自体、あんまり語り合う機会がないんじゃない?そこに危ない要素があるっていうか。
・「デジタル手法の研究をどこで発表するか」問題
天野:南谷さんは、DHと伝統的な人文学が両立するバランスの論文を書いて、そのフォーマットを作りたいとおっしゃっていました。論考にも、遠読と精読の両方、ということを書いておられました。それは、ご自身のこの編著書だから成り立ったのかもしれないなと思っていて。どうでしょう、これを外で発表するとなると、いろいろ苦労があると思いますが。
南谷:そうなんです。私はこの論集を作る時に、テキストマイニングの本を作るんだったら論者が書けるページ数を増やしてほしいと監修者の先生にお願いしたんですね。テキストマイニングの研究では分析に際してどういう方法を使ったか、どういう分析結果が出たかでほとんど終わってしまうことがあります。そこからようやく議論が始まるのにもかかわらず、DHの中だけの議論になってしまい、いわゆる精読派の研究者には届かなくなってしまうという断絶がずっとありました。なので、とにかく書ける容量を大きくして、長く書けるようにしてほしいとお願いしました。その論文のサイズ感が、精読と遠読の両方で論じることを可能にしたと言えると思います。
天野:私達が文献学で論文書くと、20ページとか30ページとか書くわけです。DHの論文って4ページとかで、このツールを使いましたで終わるっていう。DHの論文では、分析結果がどんな意味があるのかの議論はやっぱりどうしてもできないし、みんなも興味がないっていうのもある。もっと突っ込んだ議論に持って行きたかったら、やっぱり自分たちの分野に戻って来ざるを得ないというか、戻ってくることが大事なんですけど、それがなかなか難しいかなっていうことがあります。だからこういう形で一つの論考を完成されたっていうのは、凄いと思います。
オーディエンス:質問なんですけど、DHを使った人文学のご研究を出される時に、査読者ってどういう反応するんですか?こんな知らん手法で、みたいなことになったりするんですか?
天野:私はヴェーダ文献を専門にしていて、最近、統計的な分析の結果をヴェーダ学的専門的にかなり詳しく論じた論文を書きましたが、私たちの分野の普通の論文誌にはお断りされましたね。それはやっぱり査読できないからってことなのかなと思いました。統計をやったので数式やグラフが結構いっぱいあって、そういうところが避けられたのかなとは思いました。
南谷:なんかそこがすごくプラクティカルな問題になりそうだなと思いながらお話を伺いました。査読してほしいですよね。手法的な部分も含めて、おかしなことをやっていないかっていうところを実際見てもらえるとありがたいなと思います。
・生成AIによる判定の「ブラックボックス」
南谷:日本英文学会で研究発表をしたとき、2019年から2024年に出た4つのロボット小説の中に登場するロボットの直接話法のデータを集めて、生成AIを用いてその発話の「自然さ」を測定させました。そしたら2019年から2024年にかけて、右肩上がりにどんどん「自然」になるんですね。伝統的に小説の中でロボットが喋る言葉は必ず「欠損」を抱えていました。それはそのキャラクターがロボットであることを読者に認識させるためのフィクション上の仕掛けなんですが、ChatGPTみたいなものが出てきた今、フィクションの中でロボットのキャラクターがロボット的な言葉づかい、いわゆる「ロボスピーク」を話してしまうと、尤もらしさを損なってしまうことになる。なぜなら今、ロボットはそんな風に喋らないから。伝統的なロボット観がこれまでの小説には反映されてきたのですが、近年の作品にあっては、ロボットは人間と変わらない言語を喋ることになる。今後どういうふうにロボットを小説という言語による創作物のなかで人間と差異化して、あるいは差異化しないで表現していくことになるのか、という問題提起をしました。こういったことを発表で紹介した時に、その「自然さ」はどう判断するんですか?という質問はありました。データを出す時にその「自然さ」を求める条件を提示した上であったとしても、やはり自然言語の複雑さには途轍もないものがあるので、データでは回収しきれないっていう批判はこれからもあるんだろうなと思います。
天野:対話の自然さをAIが判定してくれるのは、結局何を根拠に?っていうのはもうわからないっていうことですね。私はやはり、ブラックボックスのツールは文献学にそぐわないと言うか、どうなんでしょうか。私はいまだに抵抗がすごくあって、言葉遣いの癖みたいなものを判断するツールなどもありますが、根拠が何も示されないと議論になり得ないなと思ってしまうんですが。
オーディエンス:ChatGPT筆頭に、生成AIとの付き合い方って結構分野によって違うのかなと思いました。データの解釈が発生するようなところがブラックボックスだと、確かに結構怖くなっちゃうというか。
オーディエンス:対話の自然さをどうやって量ることにするのかという指標をはっきりさせればいいような気がしますね。文の長さがばらつくとか、文脈の一貫性とか、何をもって判断したかを出力させるやり方もあると思います。
4. 次回のデジタル人文学Round Tableについて:Genbook、生成AIと文学研究
天野:話は尽きないのですが、南谷先生に今日もっと聞きたかったGenbookについてのお話を、次回じっくり聞きたいと思いますので、そのさわりのところを。
南谷:今は生成AIを用いた文学研究を手掛けていますが、特に物語作品の映像化ということに強い関心を持っています。これから大きなムーブメントがあるとすれば、それは「言葉の映像化」だと思います。例えば、伝統的な読書では私たちは言葉を「文字」として読んで、想像を膨らませて、自分の知識や経験を織り交ぜて読むわけですが、今後は文字から画像や動画が制作できるようになります。「雨」という文字から雨の音も聴こえてくるようになるでしょう。そうしたことが可能になったとき、いろんなリスクもありますけど、文学研究には大きなチャンスになると期待しています。特にショート動画を見る若い世代に対してもアピールできると思っています。来年の統合型複合科目で担当する授業では、物語作品から映像を学生たちに作ってもらう予定です。
天野:これは先生の著書で言うと、『生々流転する『ユリシーズ』の世界』とか、『洞窟の中の幻想の怪物』、このあたりのお話になりますね。これを第2回のRound Tableまでに勉強して、今度じっくりお聞きしたいと思います。本日は本当にありがとうございました。
「生々流転する 『 ユリシーズ 』 の世界ー映画から漫画、グラフィックノベル、VRまで 」『文学とアダプテーション II―ヨーロッパの古典を読む 』(春風社、 2021 年、分担執筆) 「洞窟のなかの幻想の怪物 初期恐竜・古生物文学の形式と諸特徴 」『幻想と怪奇の英文学 IV 変幻自在編 』(春風社、2020 年、分担執筆)